
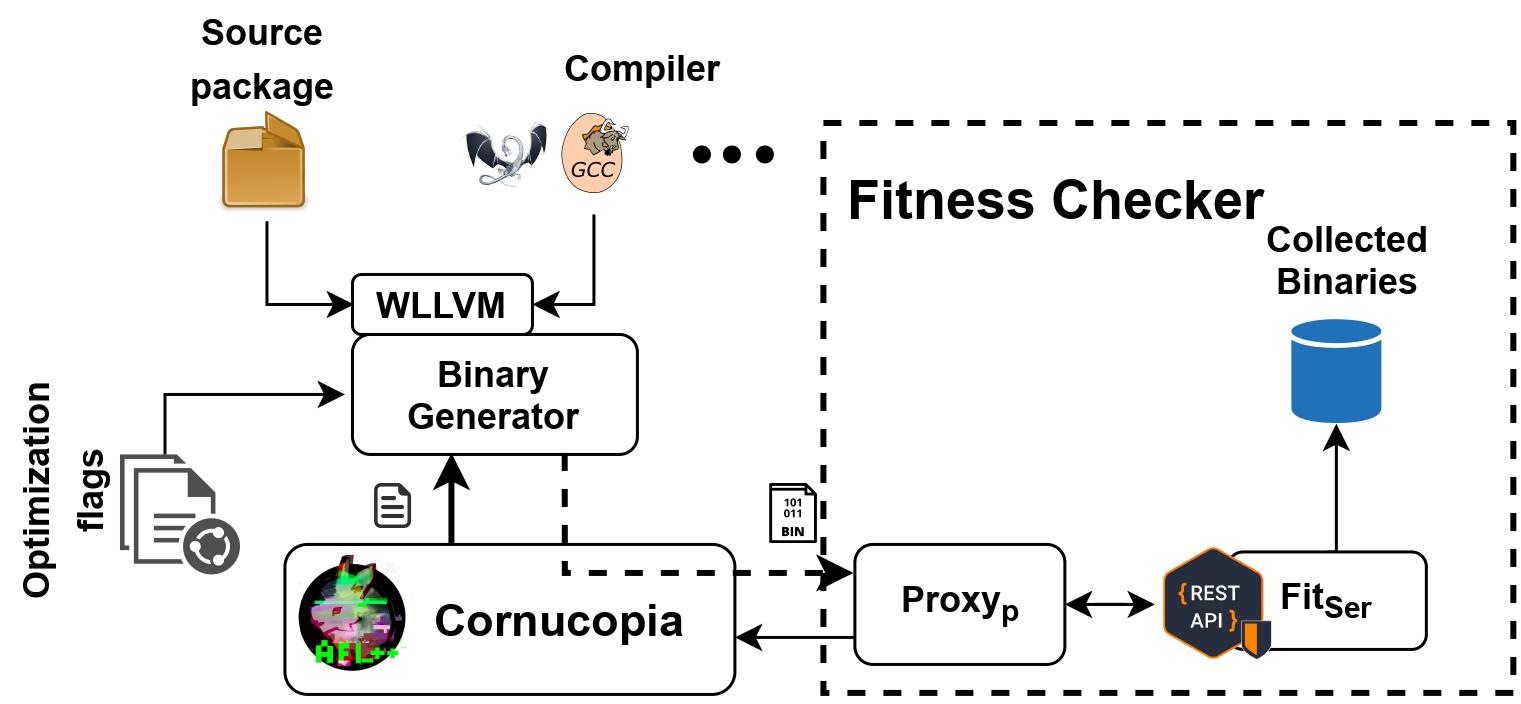
Cornucopia is an architecture agnostic automated framework that can generate a plethora of binaries from corresponding program source by exploiting compiler optimizations and feedback-guided learning. We were able to generate 309K binaries across four architectures (x86, x64, ARM, MIPS) with an average of 403 binaries for each program.
Download our dataset below:
x86
x64
ARM
MIPS
All the binaries in the dataset are unstripped (i.e., has debug symbols)
Citation
If you use our dataset, please cite our work:
@inproceedings{cornucopiaase,
title={Cornucopia: A Framework for Feedback Guided Generation of Binaries},
author={Singhal, Vidush and Pillai, Akul Abhilash and Saumya, Charitha and Kulkarni, Milind and Machiry, Aravind},
booktitle={2022 37th IEEE/ACM International Conference on Automated Software Engineering (ASE)},
year={2022},
organization={IEEE}
}
Our evaluation of four popular binary analysis tools angr, Ghidra, IDA Pro, and radare2, using these binaries, revealed various issues with these tools.
Using Cornucopia
You can use our tool to generate various binaries (semantially-equivalent) for a given program by following the below instructions.
A Docker Image for Cornucopia
This is a docker image that will build Cornucopia with all the correct dependencies installed.
To build the image execute the following command in the main directory
docker image build -t cornucopia .
The above command will build the cornucopia docker image. We can then access it and play around inside the environment. To run the docker image we just built, run the following command
docker run -p 5001:5001 -t -i cornucopia
Once we have run this command we will enter a bash terminal where all the files and folders will reside in /root. Now follow the steps below to successfully run cornucopia.
1.) Make the post-gres database, run all the command below sequentially to create the database.
service postgresql start
su postgres
psql
create database db;
create user anon with encrypted password 'admin';
grant all privileges on database db to anon;
To quit psql use \q and to quit postgres use exit.
2.) Run the server
Open a new screen to run the server in by typing screen. This will take you to a new screen.
Go to the fitness_wrapper directory and type the following command in order to deploy the server.
Note that we are using port 5001 here because that is the one that was exposed in the docker file.
Also note that we are using the function hash uniform weight server but to use another server out of the many that run different fitness functions just replace the server .py file and run it instead.
python3 server_function_hash_uniform_weight.py /root/fitness_wrapper/uploaded_files/ 5001
When you have tun the server it will show something like this:
* Serving Flask app 'server_function_hash_uniform_weight' (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on all addresses.
WARNING: This is a development server. Do not use it in a production deployment.
* Running on http://xxx.xx.x.x:5001/ (Press CTRL+C to quit)
Copy the IP address, http://xxx.xx.x.x:5001/ for example above and close the screen with ctrl A + D.
Paste this IP address in the ./automation_scripts/randollvm.config file in the SERVER_URL field. This is the address where cornucopia will send the generated files.
3.) Choose which architecture you are fuzzing LLVM for, you can choose from the following 4 architectures.
a.) x86-64
b.) x86
c.) arm
d.) mips
4.) Run option parser to get the architecture specific optimization options.
We need to run this to get the correct optimization flags for the architecture chosen.
If you choose mips for example run the following command in the /root directory where optionParser.py resides to get all the target specific options which will be outputted in the file option_list.txt.
a.) python3 optionParser.py options_list.txt mips
change mips in the command above with the architecture of choice
5.) Modify randollvm.config file in automation_scripts as per need.
Modify this file in the folder automation_scripts to fine tune the options, for instance the iterations to fuzz, threads to use, fuzzing time if you need to use time instead of iterations. Change the architecture from the ones mentioned above as well. Depending on which server you deployed enter the name of the server file name. Also, if you just want to fuzz a single bitcode file from the multiple ones that are available in afl_sources then change the name to that file for the option SOURCE in this file.
6.) Sometimes AFL++ complains about CPU governor, so it would a good idea to run the following command on your host machine outside docker.
a.) sudo echo performance | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
7.) Finally, running cornucopia with your setting
Go to the automation_scripts folder and run the following command for help on Cornucopia.
python3 run_fuzz.py --help
You need to provide the fuzz mode (1 for a single file in parallel and 0 for all files in afl_sources in parallel)
you also need to provide the config file.
For example, you can run the following command to run cornucopia for all files in parallel where each source is fuzzed on a single core, make sure that you run this command in another screen (Run this command in a separate screen using the screen command so that you can go back to the server screen and check the progress).
python3 run_fuzz.py -m 0 randollvm.config
To run cornucopia in parallel mode for just one source file use the following command, when using this mode cornucopia will use the source file that was entered in the config file.
python3 run_fuzz.py -m 1 randollvm.config
8.) To make sure that everything is running well, check the screen where you deployed the server, and you should see files being sent to it. To go back to server screen, exit the fuzzer screen using ctrl A + D. And the switch to server screen using,
screen -r <screen_num>
you can obtain screen numbers by running screen -ls.
You can also check the afl++ output in the llvm_afl_fuzz_crashes directory. If for some reason you don’t see a server output check for logs in the llvm_afl_fuzz_crashes to see what happened and why afl++ did not run.
9.) The generated file will start getting populated in the fitness_wrapper/uploaded_files/x86_64 folder. Each source will have its own folder and all the unique assembly files will be inside that folder.
10.) The server logs can also be accessed via postgresSql to see what new files were entered in the database with the corresponding time stamp.
Differential testing (Note this won’t work in the docker because of the unavailability of certain dependencies)
For the differential testing, refer to the instructions below on a local machine outside docker: All the data for the diff testing is in the folder “diff_test”.
Usage
- you will need to have
angr&r2pipeinstalled - build Ghidra from source: instructions, edit the
GHIDRA_PATHinmodels/runner.py - you will also need a licensed copy of IDA Pro, edit
IDA_PATHinmodels/runner.pyto reflect. - make sure to have unstripped versions of binaries in a folder called
unstripped - you can change tools to test in
run.py - hardcoded timeout for all tools is in
models/runner.py
python3 run.py <directory_with_stripped_binaries>
Output
- logs can be found in the
progress.log, please note that this file is also used to save progress when resuming. - In cases were differences were found output will be found in the
diff_failsdirectory - dumps of stdout and stderr can be found in the in the
crashesdirectory
Dataset
You can download the complete dataset featured in the paper from Zenodo